主题
AI 实验室项目回顾:当普通人遇上 Gemini-3-Pro
在过去的一段时间里,通过与 Gemini-3-Pro 的深度协作,快速将一些点子落地为看得见的项目。这不仅是一次技术的探索,更是一场关于“AI 如何赋能个人开发者”的生动实验。
以下是近期的核心项目回顾,每一个项目都见证了从灵感到落地的奇妙过程。
1. 一起拉屎

微信公众号标题:拉屎的时间 AI 就完成设计了,UI 设计&前端工程师危?!
虽然名字听起来有些戏谑,但这是一个严肃关注肠道健康的应用。它展示了 AI 如何帮助我们快速构建健康类应用的原型,并进行有趣的数据分析。
2. 微运动:打工人的续命急救包

微信公众号标题:作为一个牛马,越优秀身体越脆弱,因此我让 Gemini3 帮我设计了一个微运动 App,不是想要八块腹肌,仅仅是给自己续命
针对久坐办公人群设计的微运动应用。不需要复杂的器械,利用碎片化时间进行简单的拉伸和运动。这个项目体现了 AI 在解决特定人群痛点时的敏锐度和执行力。
3. 宝宝故事

微信公众号标题:【收藏级】AI 育儿革命:每个"缺点娃"都是隐藏的超级英雄!(附万能提示词),让每个"小缺点"都变成超能力
每个孩子都有自己的小特点,有时这些特点会被认为是“缺点”。这个应用利用 AI 将孩子的这些特点转化为故事中的超能力,为每个孩子定制专属的童话故事,让教育变得更加温暖和个性化。
4. 羽迹:你的 AI 羽毛球教练

微信公众号标题:吃饭的功夫,我让 AI 帮我完成了羽毛球训练助手 APP 原型“羽迹”,产品经理手里的饭瞬间不香了
利用 AI 进行动作分析和训练辅助。这个项目展示了 AI 在体育运动领域的应用潜力,帮助羽毛球爱好者更科学地进行训练,记录每一次的进步。
5. 心情记录:探索内心世界
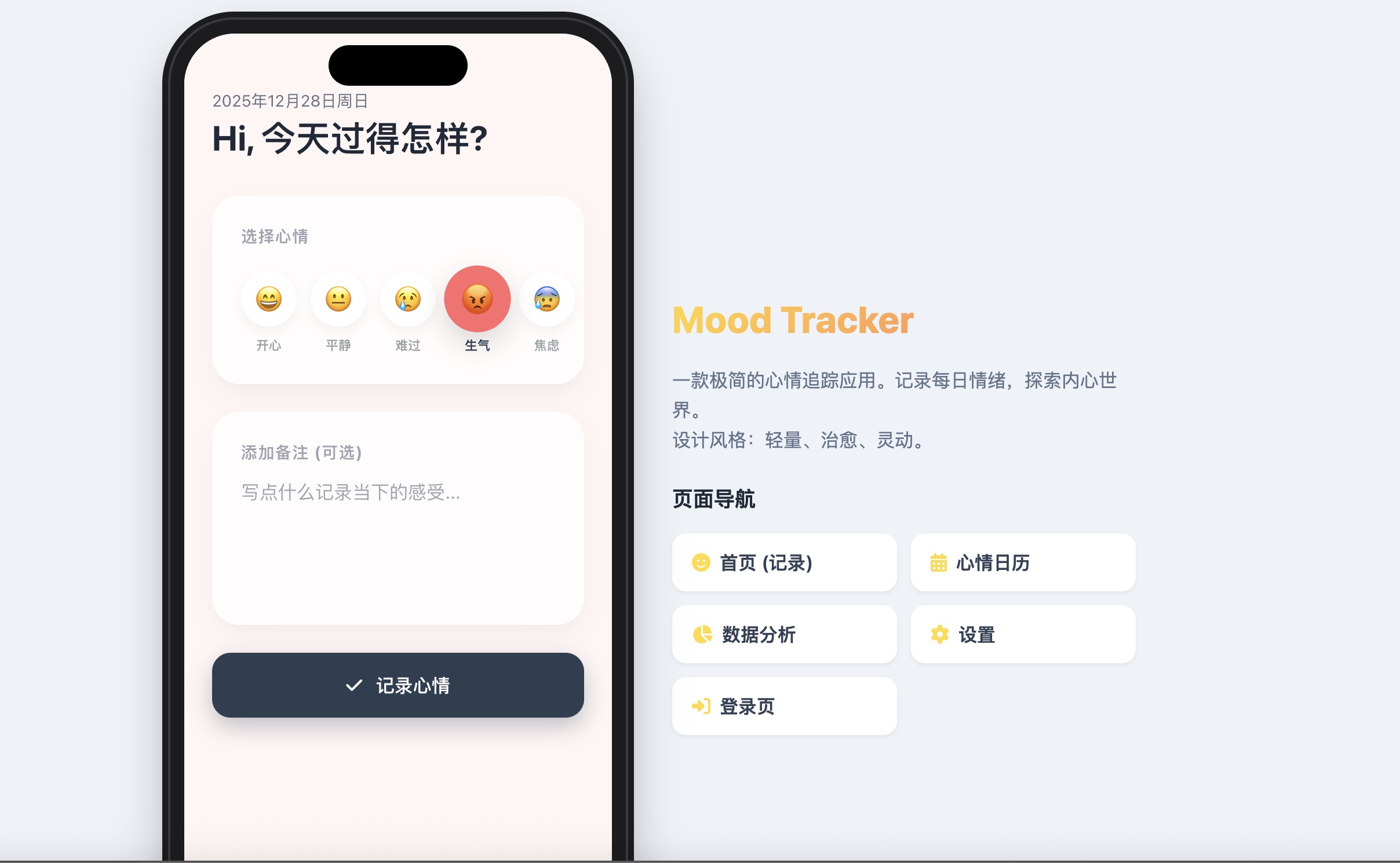
微信公众号标题:我戒掉了情绪内耗,靠的不是自律,而是 Gemini3 帮我完成的这个 APP
一个帮助用户记录和分析情绪波动的工具。通过 AI 的辅助,我们快速实现了情绪的可视化追踪,帮助用户更好地了解自己的内心世界。
6. VisualVocab:随手拍学单词

微信公众号标题:如果能把世界像贴纸一样撕下来……这个脑洞我给满分!VisualVocab: 这是我用过的最温暖、最有人情味的 AI 单词学习工具
结合图像识别与语言学习的创新应用。拍下身边的物体,即可学习相关的单词。这个项目展示了多模态 AI 在教育领域的无限可能。
7. 英语作文助手:你的 24 小时 AI 私教

微信公众号标题:程序员老父亲的周末硬核带娃:手搓 AI 英语作文批改神器,从此辅导作业不费妈!
针对中小学生英语写作辅导难、批改反馈慢的痛点。利用 AI 技术提供即时的作文批改、评分和优化建议,支持分级训练和拍照上传,让学生随时随地获得专业的写作指导。
8. 喝水吧:每天 8 杯水,健康常相伴

微信公众号标题:喝水这件小事,为什么你总是做不到?AI 帮你找到了答案
一款极简、有趣的手绘风喝水打卡应用。通过可视化的颜色反馈(从干旱的灰色到滋润的绿色)和社交激励机制,帮助用户养成每日足量饮水的健康习惯。
9. Resona 冥想空间:致每一个在深夜独自醒着的你

微信公众号标题:Resona:致每一个在深夜独自醒着的你
一个专注于陪伴的冥想应用。它不仅仅是播放白噪音,而是通过“共鸣夜灯”功能,让你感受到在这个星球的某个角落,有人正和你一起聆听。它不试图治愈失眠,而是提供温暖的陪伴,让你在孤独中找到平静。
10. 一炷香:懒人许愿

微信公众号标题:你需要“一炷香”的时间,逃离熟练的麻木
在这个喧嚣的时代,我们需要“一炷香”的时间来找回内心的秩序。这是一款极简的祈祷解压应用,通过模拟真实的烧香体验,为你创造一段神圣的“心流时间”,帮助你在忙碌中找回片刻的宁静。
11. AI 爽文生成器:像聊天一样写小说

微信公众号标题:我用 Geimi3 搓了一个爽文 APP 原型,5 分钟让小白也能写出“重生之首富前夫跪求复合”
一个让小白也能轻松创作的娱乐化写作工具。通过“聊天式创作”,用户只需要提供核心脑洞和剧情选择,AI 就会自动引导剧情走向并生成高质量的章节。它打破了写作的门槛,让每个人都能体验“当导演”的快乐,轻松写出热度 10 万+ 的爆款爽文。
- 访问地址:https://www.barebear.cn/projects/chat-novel/app/index.html
- 原型文章:5 分钟!我用 AI 搓出了一个爽文 APP 原型
- 商业洞察:为什么“爽文”是一门好生意?
12. Mystic Tarot | 神秘塔罗

微信公众号标题:不懂技术,越可能做出爆款产品:一个小白半天完成一个手势交互塔罗牌游戏的启示
这是一个结合了 3D 视觉特效、手势交互与 AI 流式解读的塔罗牌应用。通过手势控制牌阵滚动、握拳选牌、张开五指召唤 AI 解读,为用户带来极具仪式感的神秘体验。这个项目展示了如何用技术手段(手势识别、AI 大模型)去服务于情感体验,打造出“魔法”般的效果。